c++에 리터럴 주요 6개 카테고리가 있습니다. : interger, character, floating-point, string, boolean, and pointer. C++11 부터는 당신은 이러한 카테고리에 기반하는 자신만의 리터럴을 정의 할 수 있다. 이것은 통상적인 관용어에 대한 구문적인 숏컷과 타입 안정성적을 증가 시키기 위한 것이다. 예를 들어 당신은 distance 클래스를 갖고 있다고 말해보자. 당신은 킬로미터와 또다른 마일에 대한 리터럴을 정의할 수 있을 것이다. 그리고 유저들에게 이러한 단위 대해 명확하게 하는 것을 권할 것이다. : auto d = 42.0_km 또는 auto d = 42.0_mi. 사용자 정의 리터럴에 대한 이점과 단점은 없습니다. 이것은 컴파일 타임 형식 추런이나 편의성을 우선적으로 합니다. 이러한 표준 라이브러리는 <chrono> 헤더에 std:;string, std::complex 그리고 시간과 기간 연산 대한 사용자 정의를 갖습니다.
Distance d = 36.0_mi + 42.0_km; // Custom UDL (see below)
std::string str = "hello"s + "World"s; // Standard Library <string> UDL
complex<double> num =
(2.0 + 3.01i) * (5.0 + 4.3i); // Standard Library <complex> UDL
auto duration = 15ms + 42h; // Standard Library <chrono> UDLs
사용자 정의 리터럴 연산 기호
당신은 아래 형식중의 하나로 네임스페이스 범위 에서 operatr""를 이용해서 사용자 정의 리터럴을 구현합니다.
ReturnType operator "" _a(unsigned long long int); // Literal operator for user-defined INTEGRAL literal
ReturnType operator "" _b(long double); // Literal operator for user-defined FLOATING literal
ReturnType operator "" _c(char); // Literal operator for user-defined CHARACTER literal
ReturnType operator "" _d(wchar_t); // Literal operator for user-defined CHARACTER literal
ReturnType operator "" _e(char16_t); // Literal operator for user-defined CHARACTER literal
ReturnType operator "" _f(char32_t); // Literal operator for user-defined CHARACTER literal
ReturnType operator "" _g(const char*, size_t); // Literal operator for user-defined STRING literal
ReturnType operator "" _h(const wchar_t*, size_t); // Literal operator for user-defined STRING literal
ReturnType operator "" _i(const char16_t*, size_t); // Literal operator for user-defined STRING literal
ReturnType operator "" _g(const char32_t*, size_t); // Literal operator for user-defined STRING literal
ReturnType operator "" _r(const char*); // Raw literal operator
template<char...> ReturnType operator "" _t(); // Literal operator template
이전 예제의 연산자 이름은 당신이 제공하는 이름에 대한 플레이스 홀더 입니다. 앞에 언더스코어는 필수 입니다.(표준 라이브러리만 언더스코어 없이 리터럴을 정의하는 것이 가능합니다) 리턴 타입은 당신이 리터럴에 의해 수해오디는 변환이나 다른 연산자를 사용자 정의하는 곳입니다. 또한 이러한 연산들은 constexpr로도 정의될 수 있습니다.
Cooked Literals
소스코드에서 사용자 정의든 아니든 101 or 54.7, "hello", true 와 같은 알파벳 문자들 시퀀스는 필수적이다. 컴파일러는 시퀀스를 integer, float const char* string 등으로 해석한다. 컴파일러 리터럴 값으로 할당한 타입과 상관없이 입력으로 받아드려진 모든 사용자 리터럴 값은 비공식적으로 cook 리터럴로 알려진다. except _r 와 _t 위의 모든 연산자는 cooked literals이다. 예를 들어 리터럴 42.0_kim는 연산자를 _km로 바인드 시킨다. 그것은 _b 시그니처와 유사하다. 그리고 리터럴 42_kim는 연산자를 _a 시그니처와 비슷하게 바인딩 한다.
다음 예제넌 사용자 정의 리터럴이 호출자에게 사용자들의 입력에 대해 명확하게 할 것을 권하는 방법을 보여준다. Distance를 생성하기 위해서 우리는 반드시 kilometers 또는 milds를 적절한 사용자 리터럴을 사용하여 명확히 지정해야 한다. 당신은 다른 방법으로 같은 결과를 얻을 수 있다. 하지만 사용자 정의 리터럴은 다른 대안들 보다 간단한다.
// UDL_Distance.cpp
#include <iostream>
#include <string>
struct Distance
{
private:
explicit Distance(long double val) : kilometers(val)
{}
friend Distance operator"" _km(long double val);
friend Distance operator"" _mi(long double val);
long double kilometers{ 0 };
public:
const static long double km_per_mile;
long double get_kilometers() { return kilometers; }
Distance operator+(Distance other)
{
return Distance(get_kilometers() + other.get_kilometers());
}
};
const long double Distance::km_per_mile = 1.609344L;
Distance operator"" _km(long double val)
{
return Distance(val);
}
Distance operator"" _mi(long double val)
{
return Distance(val * Distance::km_per_mile);
}
int main()
{
// Must have a decimal point to bind to the operator we defined!
Distance d{ 402.0_km }; // construct using kilometers
std::cout << "Kilometers in d: " << d.get_kilometers() << std::endl; // 402
Distance d2{ 402.0_mi }; // construct using miles
std::cout << "Kilometers in d2: " << d2.get_kilometers() << std::endl; //646.956
// add distances constructed with different units
Distance d3 = 36.0_mi + 42.0_km;
std::cout << "d3 value = " << d3.get_kilometers() << std::endl; // 99.9364
// Distance d4(90.0); // error constructor not accessible
std::string s;
std::getline(std::cin, s);
return 0;
}
리터럴 숫자는 반드시 10진수를 사용한다. 그렇지 않으면 숫자는 정수형과 연산자와 호환 불가능한 타입으로 해석될 수 있다. 플로팅 포인 입력에서 타입은 반드시 long double 이여야 한다. 그리고 정수 타입에서는 반드시 longlong 타입이여야 한다.
예시: 로우 리터럴의 한계
로투 리터럴 연산자와 리터럴 연산자 템플릿은 오직 중서나 플로팅 포인트 사용자 정의 리터럴에서만 작동한다. 다른 예시에서 볼수 있듯이
문자열 리터럴은 널이 제거된 문자열을 형성하는 문자들 시퀀스를 함께 표현한다. 문자들은 반드시 쌍따옴표 안에 있어야한다. 다음에 문자열 리터럴의 종류가 있다.
좁은 문자열 리터럴
좁은 무자열 리터럴은 접두사가 없고 쌍따옴표로 구본되고, 널이 제거 된 const char[n] 타입의 배열이다. 여기서 n은 바이트 배열의 길이다. 좁은 문자열 리터럴은 싸따옴표, 백슬래쉬, 또는 개행 문자를 제외한 어떤 그래픽 문자도 포함할 수 있다. 좁은 문자열 리터럴은 또한 아래 정리된 이스케이프 시퀀스와 바이트에 맞는 범용 문자 이름 또한 포함 할수도 있다.
A UTF-8로 인코딩된 문자열은 u8-접두사가 있고, 쌍따옴표로 구분되어 있고 const char[n] 타입의 배열이다. 여기서 n은 인코딩된 바이트 배열의 길이이다. u8 접두사가 있는 문자열 리터럴은 또한 쌍따옴표, 백슬래쉬, 개행문자를 제외하고 어떤 그래픽 문자도 가질 수 있다. u8 접두사가 붙은 문자열 리터럴은 또한 아래 정리된 이스케이프 시퀀스와 어떤 범용 문자 이름을 포함 할수도 있다.
// Before C++20
const char* str1 = u8"Hello World";
const char* str2 = u8"\U0001F607 is O:-)";
// C++20 and later
const char8_t* u8str1 = u8"Hello World";
const char8_t* u8str2 = u8"\U0001F607 is O:-)";
넓은 문자열 리터럴
넓은 문자열 리터럴은 널이 없는 wchar_t배열이고 wchar_t는 L 접두사가 붙는다. 그리고 쌍따옴표, 백슬래쉬 또는 개행문자를 제외한 어떤 그래픽 문자든지 포함한다. 넓은 문자열 리터럴은 아래 정리된 이스케이프 문자 시퀀스들과 아무 범용 캐릭터 이름을 포함할 수도 있다.
C++11 은 편한 char16_6(16비트 유니코드)와 char32_t(23비트 유니코드) 문자 타입들을 소개한다.
auto s3 = u"hello"; // const char16_t*
auto s4 = U"hello"; // const char32_t*
raw 문자열 리터럴(C++11)
raw문자열 리터럴은 널이 제거된 아무 문자 타입의 배열이다. 그리고 쌍따옴표, 백슬래쉬 또는 개행문자를 포함하고 아무 그래픽 문자를 포함한다. 로우 문자열 리터럴은 캐릭터 클래스를 사용하는 정규식과 html 문자열, xml 문자열에 사용된다. 샘플에 대한건 다음 기사를 확인 하세요.Bjarne stroustrup's FAQ on C++ 11
구분자는 최대 16문자로 구성된 사용자 정의 시퀀스입니다. 구분자는 로우 스트릴 문자열의 열린 괄호 앞에 있고 그리고 닫힌 과로 뒤에 있습니다. 예를 들어 rR"abc(Hello"\()abc"에서 구분자 시퀀스 이고 문자열 내용은 Hello"\C 입니다. 당신은 당신은 로우 문자열을 명확하게 구분하는 구분자를 사용할수 있습니다. 로우 문자열은 쌍따옴표마크나 광호를 모두 포함합니다. 이런 문자열은 컴파일 에러를 일으킵니다.
// meant to represent the string: )"
const char* bad_parens = R"()")"; // error C2059
그러나 구분자는 이것을 해결합니다.
const char* good_parens = R"xyz()")xyz";
당신은 개행(이스케이프 문자가 아닌)을 포함하는 로우 문자열 리터럴을 구성할 수 있습니다.
std::string 리터럴은 "xyz"s(접미사 s)처럼 표현되는 사용장 정의 리터럴의 표준 라이브러리 구현들이다. 문자열 리터럴 종류는 std::string, std::wstring, std::u32string, 또는 std::u16string과 같은 임시 객체를 생성한다. 이들은 지정된 접두사에 의존적이다. 접두사 없이 사용될 때는 위처럼 std::string이 생성된다. L"xyz"s는 std::wstring을 생성한다. u"xyz"s는 std::u16string를 생성하고 U"xyz"는 std::u32string을 생성한다.
std::string 문자열은 <string> 헤더 파일 안에 std::literals::string_literals 네임스페이스 안에 정의되어 있다. std::literals:;string_literals와 std::literals 모두 인라인 네임스페이스로 선언되어 있기 때문에 std::literals::string_literals는 자동으로 std 네임스페이스에 직접 소유되는 것 처럼 취급됩니다.
문자열 리터럴의 사이즈
ANSI char* 문자열과 기타 단독 바이트 인코딩인 경우, 문자열 리터럴의 크기는 제거 널 문자에서 문자 숫자를 1더한 것이다. 모든 다른 문자열 타입의 경우 크기가 엄격히 문자 갯수와 관련되어 있지는 않다. UTF-8은 일부 코드 유닛을 인코드하기 위해서 char를 4개까지 사용한다. utf-16으로 인코드 된 그리고 char16_t나 wchar_t는 단독 코드 유닛을 인코드 하기 위해서 2개의 요소(총 4바이트)를 사용한다. 이 예제는 넓은 문자열 리터럴의 바이트 사이즈를 보여준다.
strlen()과 scslen()은 종료 널 문자 사이즈를 포함하지 않고 사이즈는 문자열 타입의 요소 사이즈와 동일하다 : char* or char8_t* 문자열은 1바이트, wchar_t* 또는 char16_t* 문자열은 2바이트, char32_t* 문자열은 4바이트.
문자열 리터럴으 최대 길이는 65535 바이트이다. 이 최대치는 좁은 문자열 리터럴과 넓은 문자열 리터럴에 모두 적용된다.
문자열 리터럴 수정
문자열 리터럴(std:;string을 포함하지 않는)는 상수이기 때문에 그것들을 수정하는 것은(예시_str[2] = 'a') 컴파일 에러를 발생 시킨다.
마이크로소프트 관련
C++ 마이크로소프트에서 당신으 non-const char 또는 wchar_t 포인터를 초기화기 위해 사용할 수 있습니다. 이 non-const 초기화는 c99 에서 가능합니다. 하지만 이건 c++98에서 deprecate 됐고, C++11에서 제거 됐습니다. 문자열을 수정하는 시도는 예시처럼 접근 위반을 일으킵니다.
당신은 컴파일 옵션을 /Zc:strictStrings(Disable string literal type conversion)을 설정하고 non-const 문자 포인터로 문자열 리터럴을 번경하려고 하면 콤파일은 에러를 발생합니다. 우리는 표준을 따르는 포터블 코드를 따르는 방법을 추천합니다. 이것은 문자열 리터럴 초기화 포인터를 선언하기 위한 auto 키워드를 사용하는 좋은 연습입니다. 왜냐하면 이것은 정확한 타입으로 해결합니다. 예를 들어 아래 코드 샘플은 컴파일 타임에 문자열 리터럴을 쓰는 시도를 잡아 냅니다.
auto str = L"hello";
str[2] = L'a'; // C3892: you cannot assign to a variable that is const.
어떤 경우에는 실행파일에서 공간을 절약하기 위해 동일한 문자열 리터럴은 풀링된다. 문자열 리터럴 풀링에서 컴파일러는 특정 문자열 리터럴의 모든 참조가 메모리 상의 같은 위치를 가리키게 합니다. 문자열 리터럴에 개별의 인스턴스에 대한 각각의 참조를 갖는 대신에. 문자열 풀링을 하기 위해 컴파일러 옵션 /GF를 사용해라.
마이크로소프트 관련 섹션은 여기서 끝.
인접한 문자열 리터럴의 연결
인접한 넓은 또는 좁은 문자열 리터럴은 연결된다. 여기 선언은:
char str[] = "12" "34";
다음 선언과 동일하다.
char atr[] = "1234";
그리고 이 선언과도 동일하다.
char atr[] = "12\
34";
문자열 리터럴을 지정하기 위해 내장 16진수 이스케이프 코드를 쓰는 것은 예기치 못한 결과를 일으킨다. 다음 예제는 ascii 5 문자를 초함하는 문자열 리터럴을 만들려고 한다. 그 다음 f,i,v 그리고 e를 만듭니다.
"\x05five"
실제 결과는 아스키 코드 언더스코어 16진수 5f 그리고 i, v, e 이다. 정확한 결과를 얻기 위해서는 당신은 이러한 이스케이프 시퀀스중 하나를 사용할 수 있다.
"\005five" // Use octal literal.
"\x05" "five" // Use string splicing.
std::string 리터럴(std::ustring, std::u16string, ste:;u32string과 관련된) 은 basic_string 타입으로 지정된 + 연산자를 통해 연결된다. 그들은 인접한 문자열 리터럴 또한 같은 방식으로 연결된다, 아래 모든 경우, 인코딩 문자열과 접미사는 반드시 매치되어야 한다.
auto x1 = "hello" " " " world"; // OK
auto x2 = U"hello" " " L"world"; // C2308: disagree on prefix
auto x3 = u8"hello" " "s u8"world"z; // C3688, disagree on suffixes
범용 문자 이름과 문자열 리터럴
네이티브(raw가 아닌) 문자열 리터럴은 범용 문자 이름이 하나 이상의 문자열 타입으로 인코딩 될수 있는 한 어떤 문자를 표현하기 위해서 범용 캐릭터 문자를 사용할 수도 있습니다. 예를 들어 확장 문자를 표현하는 범용문 자이름은 ansi 코드 페이지를 사용하는 좁은 문자열로 인코딩될 수 었습니다. 그러나 이것은 일부 멀티 바이트 코드 페이지나 utf8문자열 또는 넓은 문자열에서 좁은 문자열로 인코딩 될수 있습니다. c++11에서는 유니코드 서포토는 char16_t 그리고 char32_t 문자열 타입까지 확장되었습니다. 그리고 c++20은 char8_t까지 확장 시킵니다.
// ASCII smiling face
const char* s1 = ":-)";
// UTF-16 (on Windows) encoded WINKING FACE (U+1F609)
const wchar_t* s2 = L"😉 = \U0001F609 is ;-)";
// UTF-8 encoded SMILING FACE WITH HALO (U+1F607)
const char* s3a = u8"😇 = \U0001F607 is O:-)"; // Before C++20
const char8_t* s3b = u8"😇 = \U0001F607 is O:-)"; // C++20
// UTF-16 encoded SMILING FACE WITH OPEN MOUTH (U+1F603)
const char16_t* s4 = u"😃 = \U0001F603 is :-D";
// UTF-32 encoded SMILING FACE WITH SUNGLASSES (U+1F60E)
const char32_t* s5 = U"😎 = \U0001F60E is B-)";
C++ 은 다양한 문자열과 문자 타입을 지원하고 이러한 타입의 각각의 리터럴 값을 표현하는 방식을 제공합니다. 당신 코드에서 당신은 문자열 셋을 사용하는 문자와 문자열 리터럴 내용을 표현할 수 있습니다. 유니버스 문자 이름들과 이스케이프 문자들은 당신이 단지 기본 문자열 셋을 사용하면서 어떤 문자열이든 표현하게 합니다. 저수준 리터럴은 당신이 이스케이프 문자열을 피하거나 문자열 리터럴의 모든 유형을 표현하게 합니다. 당신은 또한 std::string 문자열을 추가적인 구성이나 변환 절차 없이 만들 수 있습니다.
#include <string>
using namespace std::string_literals; // enables s-suffix for std::string literals
int main()
{
// Character literals
auto c0 = 'A'; // char
auto c1 = u8'A'; // char
auto c2 = L'A'; // wchar_t
auto c3 = u'A'; // char16_t
auto c4 = U'A'; // char32_t
// Multicharacter literals
auto m0 = 'abcd'; // int, value 0x61626364
// String literals
auto s0 = "hello"; // const char*
auto s1 = u8"hello"; // const char*, encoded as UTF-8
auto s2 = L"hello"; // const wchar_t*
auto s3 = u"hello"; // const char16_t*, encoded as UTF-16
auto s4 = U"hello"; // const char32_t*, encoded as UTF-32
// Raw string literals containing unescaped \ and "
auto R0 = R"("Hello \ world")"; // const char*
auto R1 = u8R"("Hello \ world")"; // const char*, encoded as UTF-8
auto R2 = LR"("Hello \ world")"; // const wchar_t*
auto R3 = uR"("Hello \ world")"; // const char16_t*, encoded as UTF-16
auto R4 = UR"("Hello \ world")"; // const char32_t*, encoded as UTF-32
// Combining string literals with standard s-suffix
auto S0 = "hello"s; // std::string
auto S1 = u8"hello"s; // std::string
auto S2 = L"hello"s; // std::wstring
auto S3 = u"hello"s; // std::u16string
auto S4 = U"hello"s; // std::u32string
// Combining raw string literals with standard s-suffix
auto S5 = R"("Hello \ world")"s; // std::string from a raw const char*
auto S6 = u8R"("Hello \ world")"s; // std::string from a raw const char*, encoded as UTF-8
auto S7 = LR"("Hello \ world")"s; // std::wstring from a raw const wchar_t*
auto S8 = uR"("Hello \ world")"s; // std::u16string from a raw const char16_t*, encoded as UTF-16
auto S9 = UR"("Hello \ world")"s; // std::u32string from a raw const char32_t*, encoded as UTF-32
}
문자열 리터럴은 접두사가 없거나 좁은 범위 문자 utf-8, 넓은 범위 문자 utf16,utf32 인코딩과 같은 제각각의 u8, L, u 접두사를 사용합니다. 저수준 문자열 리터럴은 이러한 인코딩의 저 수준으로 대응되는 r, u8r, lr, ur과 같은 접두사를 갖을 수 있습니다. 임시거나 정적 std::string 값을 만들기 위해서 당신은 문자열 리터럴 또는 저수준 리터럴을 s 접미사와 같이 쓸 수 있습니다. 더 많은 정보는 아래에 String Literals를 보세요. 더 많은 기본 문자열 집합이나 유니버스 문자열 이름, 당신 소스코드에 확장된 코드페이지 캐릭터 사용에 대한 것은 Character sets를 보세요.
Character Literals
캐릭터 리터럴은 상수 캐릭터로 구성됩니다. 이것은 따옴표에 둘러쌓인 문자들로 표현됩니다. 다섯가지 종류의 문자 리터럴이 있습니다.
- char의 오리지널 문자 리터럴, 예시 'a'
- char(C++20에서는 char8_t) 타입의 utf8 문자 리터럴, 예시 u8'a'
- wchar_t 의 넓은 문자 리터럴, 예시 L'a'
- char16_t의 utf-16 문자 리터럴, 예시 u'a'
- char32_t의 utf-32 문자 리터럴, 예시 U'a'
문자 리터럴에 사용되는 문자는 예약된 \,', 뉴라인을 제외하면 어떤 문자도 될수 있다. 예약된 문자들은 이스케이프 시퀀스로 지정될 수 있다. 문자들 범용문자 이름으로 지정된다. 그 타입이 문자를 포함할 만큼 충분히 크다면.
인코딩
문자 리터럴은 그들의 접두사를 기반으로 다르게 인코딩됩니다.
- 접두사가 없는 문자는 오리지널 문자 리터럴 입니다. 문자셋 실행에서 표현되는 싱글 문자나, 이스케이프 문자 또는 범용 문자 이름을 포함하는 문자 리터럴의 오리지널 값은 문자셋 실행에서 인코딩의 숫자값과 동일합니다. 하나 이상 문자, 이스케이프시퀀스 또는 범용 문자 이름을 포함하는 오리지널 문자는 멀티문자 리터럴입니다. 실행 문자 세트에서 표현할 수 없는 멀티 문자 리터럴 또는 일반 문자 리터럴은 type int 와 이며 그 값은 구현 정의 입니다. MSVC에 대해서는 아래 Microsoft-specific section을 보세요.
- 접두사 L로 시작하는 캐릭터 리터럴은 광범위한 문자 리터럴이다. 싱글 문자, 이스케이프 시퀀스, 범용 문자 이름을 포함하는 광범위한 문자 리터럴 값은 문자 리터럴이 와이드 문자셋에서 표현되지 않는한 와이드 캐릭터 문자셋 실행에서 인코딩 수치 값과 동일합니다. 단 이경우 값은 구현정의됩니다.멀티 문자들과 이스케이프 시퀀스 또는 범용 캐릭터 이름을 포함하는 와이드 캐릭터 문자열의 값은 구현정의입니다. MSVC에 대해서는 아래 Microsoft-specific 섹션을 보세요.
- u8 접두사로 시작하는 문자 리터럴은 utf8 문자 리터럴이다. 싱글 문자, 이스케이프 시퀀스 또는 범용 캐릭터 이름을 포함하는 utf8 문자 리터럴 값은 utf8 코드 단독 코드 단위로 표현된다면 iso 10646 코드 포인트와 동일한 값을 갖는다. (C0 Control 과 기본 라틴 유니코드 블록에 해당). 단독 utf8 코드 단위로 표현되지 않는 값은 잘못된 형식입니다. 하나 이상의 문자, 이스케이프 시퀀스, 범용 문자 이름을 포함하는 utf8 문자 리터럴은 잘못된 형식입니다.
- u 접두사로 시작하는 문자 리터럴은 utf16 문자 리터럴이다. 단독 문자, 이스케이프 시퀀스, 또는 범용 캐릭터 이름을 포함하는 utf16값은 iso 10646 코드 포인트와 동등하다. 만약 그것이 단독 utf16코드 단위로 표현되었다면. (기본 멀티 2중 언어 플레인에 대응하는) 만약 그 값이 단독 utf16 코드 단위르롤 표현하지 않는다면 그것은 잘못된 형식이다. 하나의 이상의 문자, 이스케이프 문자열 또는 범용 문자 이름을 포함하는 utf16문자 리터럴은 잘못된 형식이다.
- U 접두사로 시작하는 문자 리터럴은 utf-32 문자 리터럴이다. 단독 문자, 이스케이프 시퀀스, 범용 문자 이름을 포함하는 utf32 문자 리터럴 값은 iso 10646 코드 포인트 값과 동일하다. 하나 이상의 문자, 이스케이프 시퀀스, 범용 문자 이름을 포함하는 utf32 문자 리터럴은 잘못된 형식이다.
Escape sequences
세 종류의 이스케이프 시퀀스가 있다. simple, octal, and hexidecimal. 이스케이프 시퀀스는 다음값 중 하나가 될 수 있다.
newline
\n
backslash
\\
horizontal tab
\t
question mark
? or \?
vertical tab
\v
single quote
\'
backspace
\b
double quote
\"
carriage return
\r
the null character
\0
form feed
\f
octal
\ooo
alert (bell)
\a
hexadecimal
\xhhh
octal 이스케이프 시퀀스는 백슬래쉬 이후의 하나에서 세개의 8진수가 나오는 시퀀스이다. octal 이스케이프 시퀀스는 세번째 진수 전에 8진수가 아닌 문자를 만난다 면 그 처음 문자에서 종료됩니다. 8진수 값의 가장 큰값은 \377입니다.
16진수 이스케이프 시퀀스는 백슬래쉬 다음에 x 그 다음에 하나 이상의 16진수가 옵니다. 앞의 0은 무시된다. 일반문자나 u8 접두사 캐릭터 리터럴에서 최대 16진수 값은 0xFF이다. L 또는 u 넓은 캐릭터 리터럴에서의 최대 16진수 값은 0xFFFF 이다. U 접두사 넓은 캐릭터 맅럴에서 최대 16진수 값은 0xFFFFFF이다.
다음 샘플 코드는 일반문자 리터럴을 사용하는 이스케이프 캐릭터 예제를 보여준다. 다른 문자 리터럴 타입에도 동일한 이스케이프 시퀀스 구분은 유효합니다.
백슬래쉬 문자는 라인 끝에 위치 하면 라인 지속 문자인다. 만약 당신이 백슬래쉬를 캐릭터 리터럴로 표현하길 원한다면 당신은 반드시 행에 2개의 백슬래쉬를 사용해요한다. 라인 지속 문자에 대해 더 알고 싶으면 봐라 Phase of Thranslation
마이크로소프트 관련
좁은 멀티문자 리터럴에서 값을 만들기 위해서는 컴파일러는 문자나 문자 시퀀스를 반점 사이에서 32bit integer에서 8bit로 변경합니다. 리터럴에 멀티 문자는 높은 순에서 낮은순으로 요구되는 바이트에 대응하여 채웁니다. 그리고 컴파일러는 정수형을 보통의 규칙에 따라 목적지 타입으로 변경합니다. 예를 들어 char 값을 만들기 위해서 컴파일러는 낮은 순서의 byte를 갖습니다. wchar_t, char16_t를 만들기 위해서는 컴파일러는 낮은 순서 워드를 갖습니다. 컴파일러는 어떤 비티는 할당돤 바이트나 워드 위에 설정된다면 결과는 잘릴 수 있다고 경고합니다.
char c0 = 'abcd'; // C4305, C4309, truncates to 'd'
wchar_t w0 = 'abcd'; // C4305, C4309, truncates to '\x6364'
int i0 = 'abcd'; // 0x61626364
3개이상의 진수를 포함하는 것을 나타내는 8 이스케이프 시퀀수는 3 진수 8 시퀀스로 다뤄집니다. 그 다음 진수는 멀티문자 리터럴에 문자로 취급됩니다. 그것은 놀라운 결과를 나타냅니다. 예시.
\377보다 더 큰 8진수 이스케이프 시퀀수는 에러 c2022를 발생합니다. '10진수값":매우 큰 문자.
16진수나 16진수가 아닌 문자를 갖은 것으로 보이는 이스케이프 시퀀스는 마지막 16진수 문자까지 16진수를 포함하는 멀티 문자로 평가됩니다. 16진수를 포함하지 않는 16진수 이스케이프 시퀀스는 컴파일 에러 c2153을 발생 시킵니다. "16진수 리터럴은 반드시 최소한 하나의 16진수를 가져야 한다"
문자 리터럴과 네이티브 문자열 리터럴에서 어떤 문자나 범용 문자 이름을 나타낼 수 있다. 범용 문자 이름은 \U 접두사를 갖고 그 다음 8진수 유니코드 포인트가 오거나 \u접두사를 갖고 그다음 4진수 유니코드 포인트가 오는 형식을 갖는다. 모든 8진수 4진수는 개별적으로 더 나은 유니버셜 문자 이름 형식을 만들기 위해 제시된다.
범용 문자 이름은 대리 코드 포인트 범위 D8000-DFFF에서 값을 인코드 하지 않습니다. 유니코드 대리 쌍에서 특히 \UNNNNNNNN을 사용한 범용문자이름에서 NNNNNNNN은 문자에 대한 8진수 코드 입니다. 컴파일러는 필요하다면 대리 페어를 생성합니다.
C++ 03에서 일부 문자에만 범용문자이름을 나타나 내느 것을 허용 했고 일부 범용문자이름은 실제로 일부 적합한 유니코드 문자들을 표현하는 것이 불가능합니다. 이런 실수는 c++11 기준에 수정되었습니다. C++11에서는 문자 그리고 문자열 리터럴 그리고 식별자까지 모두 범용 문자 이름을 사용할 수 있습니다. 범용문자이름에 대한 더 많은 정보는 CharacterSets을 참고하세요. 유니코드에 대한 정보는 Unicode를 보세요. 대리쌍에 대한 더많은 정보는 Surrogate Pairs and Supplementary Characters를 보세요.
리터럴은 값을 직접 표현하는 프로그램 요소입니다. 이 기사는 interger 타입, 부동소수점, 불리언, 포인터의 리터럴들을 설명합니다. 문자열과 캐릭터 리터럴들에 대한 정보는 여길 String and Character Literals(C++)을 확인하세요. 당신은 또한 이러한 카테고리중에 기초하여 자신의 리터럴을 정의할 수도 있습니다. 더 많은 정보는 User-defined Literals(C++)을 참고하세요.
const int answer = 42; // integer literal
double d = sin(108.87); // floating point literal passed to sin function
bool b = true; // boolean literal
MyClass* mc = nullptr; // pointer literal
때로 컴파일러에게 리터럴을 해석하거나 리터럴에 부여할 특정 유형을 알려주는 것은 중요합니다. 이것은 리터럴의 접두사나 접미사를 붙이면 됩니다. 예를 들어 접두사 0x 는 컴파일레에게 숫자를 16진수 값으로 해석하도록 합니다. (ex example0x35). ULL 접미사는 컴파일레에게 5894345ULL 처럼 unsignedLongLong 값으로 처리하도록 합니다. 각 리터럴 타입의 데한 접두사와 접미사 목록을 알고 싶으면 다음 섹션을 보세요.
Interger Literals
정수형 리터럴은 숫자로 시작되고 분수나 지수 부분이 없습니다. 당신은 정수형 숫자를 십진수, 이진수, 16진수 형태로 지정할 수 있습니다. 당신은 선택적으로 정수형 리터럴을 unsigned 형태로 지정할 수 있고 접미사를 사용하여 long이나 longlong과 같은 타입으로 지정할 수도 있습니다.
접두사, 접미사가 없는 현제 컴파일러는 정수형 리터럴 타입을 int로 지정합니다. 그 값이 맞다면, 그렇지 않으면 long long 타입으로 지정합니다.
십진수 정수형 리터럴로 지정하기 위해서 nonzero digit을 지정하는 것을 시작해라. 예시.
int i = 157; // Decimal literal
int j = 0198; // Not a decimal number; erroneous octal literal
int k = 0365; // Leading zero specifies octal literal, not decimal
int m = 36'000'000 // digit separators make large values more readable
8진수 integral 리터럴로 지정은 0으로 시작하고 그뒤에 0에서 7사이의 숫자가 놓인다. 8과 9는 8진수 리터럴을 지정할 때 에러이다. 아래 예시
int i = 0377; // Octal literal
int j = 0397; // Error: 9 is not an octal digit
16진수 정수 리터럴을 지정하기 위해서는 0x 나 0X로 시작하고(x의 대/소는 상관없음) 뒤에 0에서 9 그리고 a/A에서 f/F 범위 내에서 숫자가 온다. 16진수 a/A ~ f/F는 10~15값을 표현한다. 아래 예시
int i = 0x3fff; // Hexadecimal literal
int j = 0X3FFF; // Equal to i
숫자 구분자 : 당신은 따옴표 문자를 이용하여 사람이 읽기 편하게 커다란 숫자의 공간을 구분할 수 있습니다. 구분자는 컴파일에 아무런 영향을 주지 않습니다.
long long i = 24'847'458'121
부동 소수점 리터럴
부동소수점 리터럴은 분수부분을 같는 값을 지정합니다. 이러한 값들은 소수점(.)을 포함하고 지수를 포함합니다.
부동소수점 리터럴은 숫자의 값을 지정하는 가수를 갖는다. 또한 숫자의 크기를 나타내는 지수부를 갖습니다. 그리고 그들은 선택적인 중위표현식을 갖습니다. 그것은 리터럴 타입을 지정합니다. 가수부는 마침표 앞에오는 숫자들이 거나 숫자의 분을 나타내는 숫자들로 지정됩니다. 아래 예시
18.46
38.
지수는 아래 예제에서와 같이 10의 거듭제급으로 숫자의 크기를 지정합니다
18.46e0 // 18.46
18.46e1 // 184.6
지수는 e 또는 e를 사용하여 지정될 수 있고, 그것들은 같은 의미를 갖습니다. 그 다음에 옵션으로 +또는 -기호와 숫자 순서를 사용할 수 있습니다. 만약 지수가 존재하면 추적하는 소수점은 18E0과 같은 숫자에서 필요 없다.
부동소수점 리터럴은 double 타입을 기본으로 한다. 접미사 f 또는 l 또는 F 또는 L를 (대소문자는 상관없다) 사용하여 리터럴은 float나 longdouble로 지정될 수 있다.
비록 longdouble과 double은 같은 표현을 하지만 그들은 같은 표현이 아니다. 예를 들어 당신은 이와 같이 오버로드 할수 있다.
void func( double );
그리고
void func( long double );
불리언 리터럴
불리언 리터럴은 true와 false이다.
포인터 리터럴(C++11)
C++ 0 초기화 포인터를 지정하는 nullptr을 소개합니다. 유연한 코드에서는 nullptr가 정수형 0이나 매크로 NULL 대신에 사용 되어야합니다.
이진 리터럴(C++14)
이진 리터럴은 0b 나 0B를 사용하여 지정됩니다. 그 다음에 1과 0의 숫자 순서가 업니다.
auto x = 0B001101 ; // int
auto y = 0b000001 ; // int
매직 상수로서의 리터럴을 피하라
당신은 직접적으로 표현식이나 구문을 사용할 수 있다. 비록 그게 항상 좋은 프로그래밍 방식이 아니라고 해도.
if (num < 100)
return "Success";
앞에 예시에서 더 나은 방식은 이름이 있는 상수(명확한 의미를 전달하는)를 사용하는 것이다. 예를 들어 "MAXIMUM_ERROR_THRESHOLD"와 같은. 만약 마지막 사용자가 "Success"라는 리턴 값을 본다면 명명된 문자열 상수를 쓰는게 더 좋을 수 있다. 당신은 다른 언어로 번역가능한 파일의 단독 위치에 문자열 상수를 사용할 수 있다. 명명된 상수를 사용하는것은 당신과 다른 사람들에게 코드의 의도를 이해하는데 도움을 준다.
“Well”은 여러 가지 용도로 쓰입니다. 먼저, 당신이 지금 생각하는 중이라는 것을 보여줄 때 사용할 수 있습니다.
“Well, I guess $20 is a good price for a pair of jeans.”
말을 하는 중간에 잠시 쉬어갈 때도 쓸 수 있습니다.
“The apples and cinnamon go together like,well, apples and cinnamon.”
그리고 심지어 단순히 시간을 벌기 위해서도 쓸 수 있습니다.
“Well… fine, you can borrow my car.”
2. Um/er/uh
“Um”, “er”, “uh”는 망설일 때 가장 많이 쓰이는 표현입니다. 정답을 잘 모를 때, 혹은 대답하고 싶지 않을 때 쓸 수 있죠.
“Um,er, Iuhthought the project was due tomorrow, not today.”
셋을 동시에 쓸 필요는 없으며 원할 때 아무거나 하나를 골라 사용해도 좋습니다.
“Umm… I like the yellow dress better!”
3. Hmm
“Hmm”은 생각하는 중일 때 나오는 소리입니다. 당신이 고민 중이라거나 무언가를 결정하는 중이라는 걸 표현하죠.
“Hmm, I like the pink bag but I think I’ll buy the black one instead.”
4. Like
“Like”는 정확한 정보가 아니라, “그 비슷한”, “그 언저리의”라는 뜻으로 쓰입니다.
“My neighbor hasliketen dogs.”
위의 예문에서 이웃이 정확히 10마리의 개를 키우고 있는지는 확실하지 않습니다. 그냥 개의 마릿수가 많은 것이죠.
그리고 like는 말을 하는 도중 이다음에 쓸 말을 생각해내기 위해 시간을 조금 벌어야 할 때도 자주 사용됩니다.
“My friend waslike, completely ready tolikekick me out of the car if I didn’t stop using the word‘like’.”
영어 추임새 용도의 “like”는 영어 원어민들 사이에서 일반적으로 부정적인 인식이 있습니다. 주로 나이 어린 여자들이 문맥과 상황을 고려하지 않고 남용하는 경향이 있고, 또 이렇게 like를 과하게 사용하다 보면 본인이 하는 말에 확신이 없다는 이미지를 줄 수 있기 때문입니다.
5. Actually/Basically/Seriously
“Actually”, “basically”, “seriously”는 모두 부사입니다. 동사를 꾸며주는 역할을 하죠. 많은 부사 단어 끝에는 “-ly”가 있기 때문에 알아보기도 쉽습니다. 이 모든 단어들은 말 어감상의 변화를 줄 때 추임새로서 쓰일 수 있습니다.
예를 들어 “actually” 같은 경우, 남들은 아니라고 할 수도 있지만 당신이 진실이라고 생각하는 것을 가리킬 때 사용할 수 있습니다:
“Actually, pugs are really cute!”
“Basically”와 “seriously”는 문장을 살짝 다른 방향으로 틀어 주는 역할을 합니다. “Basically”는 무언가를 요약할 때 쓰고, “seriously”는 지금 하는 말을 진심으로 하는 것임을 표현할 때 쓸 수 있습니다.
“Basically, the last Batman movie was seriously exciting!”
추임새로 쓰이는 다른 부사로는 “totally”, “literally”, “clearly”등이 있습니다.
“literally”는 “글자 그대로”라는 의미가 있지만 대부분의 경우 대화에서는 다른 의미로 쓰입니다. 아주 강한 감정을 표현할 때 쓰이죠. 예: you’re not just laughing you’re literally dying from laughter.
“Totally”는 “completely”와 동의어이고 무언가에 대해 강조할 때 쓰입니다.
“clearly”는 obviously와 동의어이고 무언가가 명백하게 진실일 때 사용되는 말입니다.
이 세 단어 역시 한꺼번에 사용할 필요는 없지만 아래 예문에서는 여러분의 이해를 돕기 위해 한 곳에 넣어봤습니다:
“Clearlyyoutotallydidn’t see me, even though I wasliterallyin front of your face.”
6. You see
“You see”는 청자가 모르고 있다고 생각하는 사실을 공유할 때 사용됩니다.
“I was going to try the app, butyou see, I ran out of space on my phone.”
7. You know
“You know”는 청자가 이미 알고 있을 거라고 생각하는 어떤 사실을 말할 때 사용됩니다.
“We stayed at that hotel,you know, the one down the street from Times Square.”
청자가 당신이 하는 말을 이해했다고 느꼈을 경우 긴 설명 대신 이 한마디로 대신할 수 있습니다.
“When the elevator went down, I got that weird feeling in my ears,you know?”
8. I mean
“I mean”은 무언가에 대한 당신의 생각과 의도를 명확히 하고 싶을 때 씁니다.
“I mean, he’s a great guy, I’m just not sure if he’s a good doctor.”
또는 앞서 말을 잘못했을 경우 이를 정정할 때도 쓰입니다.
“The duck and the tiger were awesome but scary.I mean, the tiger was scary, not the duck.”
“The cave is two thousand—I mean—twenty thousand years old!”
9. You know what I mean?
“You know what I mean?”은 내가 하는 말을 청자가 잘 따라오고 있는지 확인차 물을 때 쓰는 말입니다.
“I really like that girl,you know what I mean?”
10. At the end of the day
“At the end of the day”는 “in the end” 또는 “in conclusion”의 동의어입니다.
“At the end of the day, we’re all just humans, and we all make mistakes.”
11. Believe me
“Believe me”는 자기가 하는 말을 믿으라는 의미에서 하는 말입니다.
“Believe me, I didn’t want this tiny house, but it was the only one I could afford.”
곧 할 말을 강조할 때 사용하기도 합니다.
“Believe me, this is the cheapest, tiniest house ever!”
12. I guess/I suppose
“I guess”와 “I suppose”는 당신이 무언가를 말하기 망설이고 있거나 확인이 잘 안 설 때 붙이는 말입니다.
“I was going to eat dinner at home, butI guessI can go eat at a restaurant instead.”
“I guess”는 구어체로 많이 쓰이지만 “I suppose”는 조금 더 예스러운 표현처럼 들릴 수도 있습니다 (조금 더 배운 사람 같은 표현이랄까요).
13. Or something
“Or something”은 문장 맨 끝에 붙이며, 정확한 정보를 모를 때 쓸 수 있습니다.
“The cake uses two sticks of butter and ten eggs,or somethinglike that.”
14. Okay/so
“Okay”와 “so”는 주로 말 첫머리에 쓰며 새로운 주제로 넘어간다는 표시로 쓰입니다.
“Sowhat are you doing next weekend?”
여태까지의 일을 요약할 때 말 첫머리에 쓰기도 하죠.
“Okay,sowe’re going to need to buy supplies for our trip this weekend.”
“Right, so let’s prepare a list of all the things we’ll need.”
“Uh huh, that’s exactly what he told me too.”
좋아요. 여기까지 배우셨으니 이제 여러분은 영어 추임새의 전문가가 다 되셨을 겁니다! 오늘 배운 단어들은 영어 추임새인 만큼, 특히 의미가 오묘하고 문맥에 따라 달라지는 경우가 많아 정확한 용법으로 쓰기 어려울 수 있습니다. 하지만 영어 추임새의 용법을 제대로 마스터하면 머지않아 영어 원어민이 말하는 것 유창한 영어를 구사할 수 있게 될 것입니다.
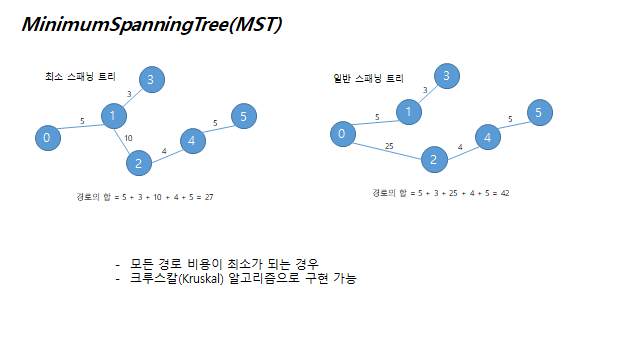
- DisjointSet data Structure를 사용하면 서로 다른 원소들이 어떤 집합에 속해 있는지를 판단하기에 유용하다.
- 정의에 의해 Disjoint Set 사이에는 교집합이 없기 때문에, 합 연산을 하는 과정에서 두 집합 사이의 겹치는 원소를 특별히 고려하지 않고 모든 원소들을 하나의 집합으로 합치는 것이 가능하다. 이 합하는 과정과 각 원소들이 어떤 집합 속에 있는지 판별하는 과정을 효율적으로 찾기 해서 Disjoint Set Union을 사용합니다.
DisjointSet은 트리를 이용하여 표현할 수 있습니다.
벡터를 이용한 DisjointSet 트리 구조 표현
Union 합치기
일반적으로 아래와 같이 합치기 연산을 진행 했을 때는 O(N) 시간 복잡도를 갖게 됩니다.
void Merge(int u, int v)
{
u = Find(u);
v = Find(v);
if (u == v)
return;
_parent[u] = v;
}
랭크압축(Rank Compression) 통한 최적화
void Merge(int u, int v)
{
u = Find(u);
v = Find(v);
if (u == v) // 대장이 같은지 체크
return;
if (_rank[u] > _rank[v])
::swap(u, v);
_parent[u] = v;
if (_rank[u] == _rank[v])
_rank[v]++;
}
Find 찾기
일반적으로 아래와 같이 소속을 찾는 함수를 구현하게 되면 Find 함수가 호출될 때마다 재귀가 호출되므로 비효율 적입니다
int Find(int u)
{
if (u == _parent[u])
{
return u;
}
return Find(_parent[u]);
}
경로압축(Path Compression)을 통한 최적화
아래와 같이 소속을 찾는 함수가 호출하게 되면 u의 parent를 root parent로 바꿔주는 경로압축을 통해 이후에 호출되는 Find(u) 함수는 빠르게 탐색이 가능하게 됩니다.
int Find(int u)
{
if (u == _parent[u])
{
return u;
}
return _parent[u] = Find(_parent[u]);
}